
Locking Redis clients for distributed calculations.
Sometimes we could miss something small but quite powerful and useful in some project. For me it was “redis connection name” - which for first look seems like smth super specific and just for meta information.
Here I will try to explain how redis connection name could help you to process a lot of data in super “safe” mode.
Redis set connection name - it’s a way to specify some name/key/id to your redis connection. Plus, you can extract all clients info using client list command.
Together these commands can be useful for analytic porpose. For example in Todoist we have redis workers for background tasks. And using redis connection name we could understand amount of processes which producing and consuming jobs.
But I found that redis connection name could be in some way a “global lock” beetwen multiple processes in redis. What does it means “a global lock”?
Redis has a multiple ways to lock data when you want to write something from multiple processes (using lua script or watch command). But what if you want
to “assign” the whole process working with some key? In this case watch command will be not efficient and lua script is not working at all.
Image if you will be able to “assign” some process only to specific key (or value inside complex keys, e.g. hash or bitmaps). I think redis set connection name could help you with this in some way. To make this happen you can specify redis connection name for some process and then check on what other processes are working on:
redis_pipeline = redis_client.pipeline()
# getting all redis clients
redis_pipeline.client_list()
# set current connection name with some unique key
# which identify the process
redis_pipeline.client_setname(unique_key)
client_list, _ = redis_pipeline.execute()
if unique_key in client_list:
print("Key already used by other process")
As you can see ^ we are trying to get clients list with already specified unique keys and then set redis connection name for current process in one transaction. As a result we will have information about all running processes and then we just need to check if current unique key there.
To complex? Let’s check an example of how this method could help you to read the database in distribute/parallel way in super safe mode:
Image we have a sql table which we want to put in redis list (use it as a queue) and then calculate something in parallel way. The main goal is to read this table using multiple processes and make whole system super “safe”.
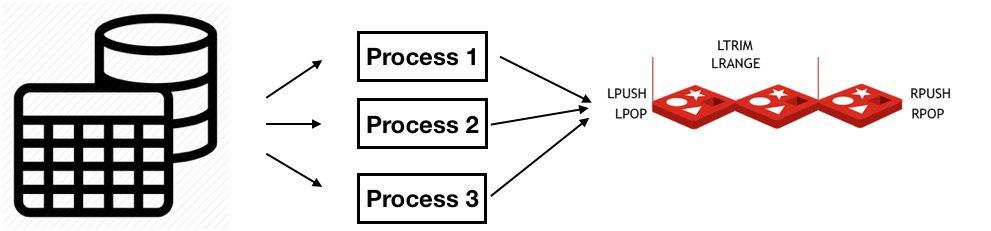
What does it mean “super safe”? We should not:
- Lose any data (on a way from table to redis).
- Duplicate any data.
- Don’t lose and duplicate data if something failed (even someone cut the power :) ).
I will try to explain my solution based on redis connection name:
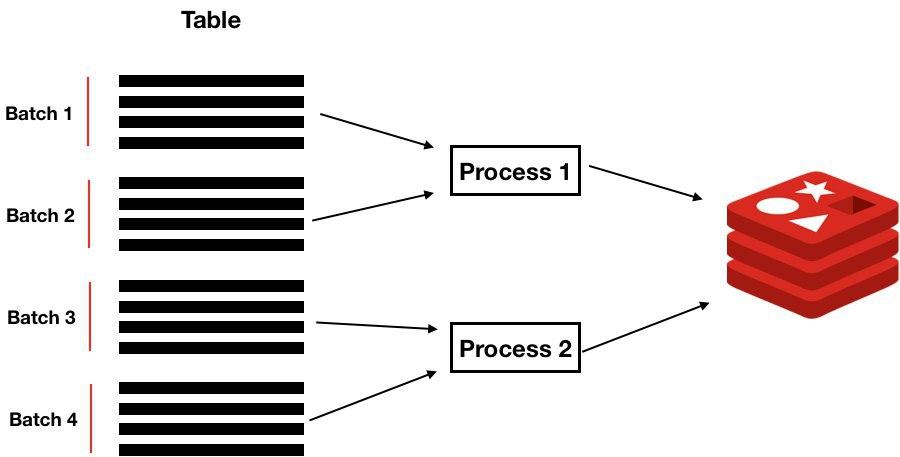
Step1. Split table by batches.
Let’s split whole table by bathes/chunks and then iterate over table rows in batch and push everything (in one commit) to redis list:
for chunk_index in range(CHUNKS_COUNT):
# generate batch "borders" based on chunk index
l_id = CHUNK_SIZE * chunk_index
r_id = CHUNK_SIZE * (chunk_index + 1)
# reading batch of data from table
mysql_cursor.execute(
"SELECT * "
"FROM table "
"WHERE id >= %s and id < %s" % (l_id, r_id))
# it's important to use pipeline here, because in case
# of failure during reading process some tasks could be left
# in list, some will be not processed (which in future will
# call data loss or duplication)
redis_pipeline = redis_client.pipeline()
for row in mysql_cursor:
redis_pipeline.lpush("rows", row)
redis_pipeline.execute()With “redis pipeline” seems like code could meet all requirements, BUT:
-
We can’t read batches in “parallel way”, because processes will just read them from 1..CHUNKS_COUNT simultaneously and duplicate all data.
-
What if something happened inside cursor iteration? The process had beed stopped and data not delivered to redis. When we decide to “repeat” reading process for this batch we will not aware of what batch we should “repeat”
Step2. Tag processed batches.
Let’s try to solve the problems above using redis bitmap. We could set bit to 1 if batches had processed and 0 otherwise.
for chunk_index in range(CHUNKS_COUNT):
# let's see if we already processed this chunk of data
bit = redis_client.getbit("chunks", chunk_index)
# if amount of bits set to 1 more then CHUNKS_COUNT
# seems like we processed everything
if redis_client.bitcount("chunks") > CHUNKS_COUNT:
break
if bit == 1: continue
l_id = CHUNK_SIZE * chunk_index
r_id = CHUNK_SIZE * (chunk_index + 1)
redis_pipeline = redis_client.pipeline()
mysql_cursor.execute(
"SELECT * "
"FROM table "
"WHERE id >= %s and id < %s" % (l_id, r_id))
for row in mysql_cursor:
redis_pipeline.lpush("rows", row)
# Mark chunk as "processed" in the same pipeline where
# we send data to redis.
redis_pipeline.setbit("chunks", chunk_index, 1)
redis_pipeline.execute()Ok, now this looks much better! We could run this script multiple times (in multiple processes) and read dat ain parallel way.
If something failed in “cursor” iterator we could just run this script again and it will find none processed batches. It looks like
we are close to our goal. BUT :)
If we run this script simultaneously chunk_index for two processes will be set to 0 -
and these processes will get 0 from redis_client.getbit and will start to process this chunk simultaneously - which will generate data duplication. (You could think about random - but it’s not a 100% solution at all).
Step3. Time for redis connection name.
What if we could “lock” some chunks and do not process them simultaneously. Here how redis connection name could help as to “lock” smth:
redis_pipeline = redis_client.pipeline()
# getting all redis clients
redis_pipeline.client_list()
# set current connection name (specified as a chunk id)
redis_pipeline.client_setname("chunk_%s" % chunk_index)
client_list, _ = redis_pipeline.execute()What happened there?
- We are trying to get clients information in first command
- And then set current connection name to some “id”. (Setting connection name will be executed after client_list command)
Now we could just check if current chunk already “booked” by someone:
# Continue if current chunk already "booked" by
# some other process
clients_names = [c['name'] for c in client_list]
if "chunk_%s" % chunk_index in clients_names:
continueWhole code:
for chunk_index in range(CHUNKS_COUNT):
# let's see if we already processed this chunk of data
bit = redis_client.getbit("chunks", chunk_index)
# if amount of bits set to 1 more then CHUNKS_COUNT
# seems like we processed everything
if redis_client.bitcount("chunks") > CHUNKS_COUNT:
break
if bit == 1: continue
redis_pipeline = redis_client.pipeline()
# getting all redis clients
redis_pipeline.client_list()
# set current connection name (specified as a chunk id)
redis_pipeline.client_setname("chunk_%s" % chunk_index)
client_list, _ = redis_pipeline.execute()
# Continue if current chunk already "booked" by some
# other process
clients_names = [c['name'] for c in client_list]
if "chunk_%s" % chunk_index in clients_names:
continue
l_id = CHUNK_SIZE * chunk_index
r_id = CHUNK_SIZE * (chunk_index + 1)
redis_pipeline = redis_client.pipeline()
mysql_cursor.execute(
"SELECT * "
"FROM table "
"WHERE id >= %s and id < %s" % (l_id, r_id))
for row in mysql_cursor:
redis_pipeline.lpush("rows", row)
# Mark chunk as "processed" in the same pipeline where
# we send data to redis.
redis_pipeline.setbit("chunks", chunk_index, 1)
redis_pipeline.execute()Now you can run this script in multiple processes and it will be super “safe” and fast.
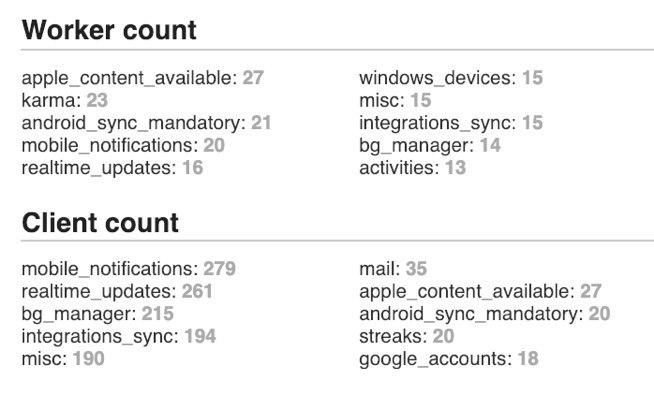
Here an example how it works in Stairs
Quite important to know that it will work only in case if your process has one thread and one redis connection which used for naming, otherwise there is a chance that client name will be overwritten.
Why lua script didn’t work here?
If you have any questions/comments/suggestions please feel free to reach me.
Enjoy :)