
Why/How ETL able ot solve a wide range of tasks.
Plan:
- Why ETL is not only about coping data from one place to another?
- Why we need ETL along with data pipelines?
- What tasks we can solve using ETL + data pipelines approach ?
- What next ?
Why ETL is not only about coping data from one place to another?
ETL. What you know about ETL?
If you just google this, you will find a lot of articles which will explain
you how to build a complex system for copy data from one place to another.
Basically that’s why it’s about Extract -> Transform -> Load.
Coping data from one place to another, hhmmm, Boring, right ?
What if I tell you that you can use ETL pattern/concept for solving almost all tasks which we have in programming field.
Here why:
Extract
First part of this concept is about extracting or getting data from some source, but from practical point of view you can extract data from any places you want:
- Database
- File
- Web request
- Command line
- Streaming service
No matter where you have your data, if it sitting somewhere - you can extract it.
Load
From wiki: “The load phase loads the data into the end target,”. But your target (similar to data source) could be anything you want:
- Database
- Web request
- Streaming service
- Neural Network
- …
It’s just infinitive list of places where you can send your results data. Even for web request - when client sends data to your server he blocks connection and waiting for response, so on the final stage you can load data back to the client.
Transformation
It’s basically all about changing, filtering and processing your data. You can do this in any ways as you want.
BUT
One of the core idea here that you did NOT change a global state and not making Side effects. But from my point of view during transformation you are completely free to load more data from different sources. This is did not change anything.
As a result
If we can get data from any places we want, then transform this data in any ways we want, and then load data in any target we want - This basically means that we can solve any tasks we want (!)
Please remember that ETL is a pattern (or concept) it’s not a tool which used only for specific range of task. You are completely free to apply this concept for any tasks/problems which you want.
For example, in case of web requests you can make something like following:
- Getting data from socket (http/tcp… request) (Extract)
- Getting data from models based on some business logic (Extract)
- Transform data, without side effects (Trasform)
- Load data to database (Load)
- Load result data (response) back to the socket (which was blocked, e.g. using async approach) (Load)
Why it’s useful and what the differents?
It’s simple, transformation step in this case never change any states it’s
basically produce new types of data or change input values.
In other words transoformation state preparing or aggregating data which
will be loaded to the store/another source in a completely isolated enviroment.
If it will be possible to isolate “load” step, we will be able to build much more intuitive, stable and fault tolerance systems.
How to run “load” steps in “isolated” environment, here we are:
Why we need ETL along with data pipelines?
The problem with row ETL that it’s really hard to follow this concept using imperative programing, especially if you want to scale your system. You need something which will have atomic components, will be easy to scale, and understand. 🤔
What if Data pipelines? (checkout my blog post about Data pipelines here).
Each of your step inside data pipeline could be completely isolated from everything else (thanks for queues/workers/streaming concept) and will have one direction from save to load. So you can easily split your system by Extract -> Transform -> Load steps, and have a very clear vision of what going on in your system.
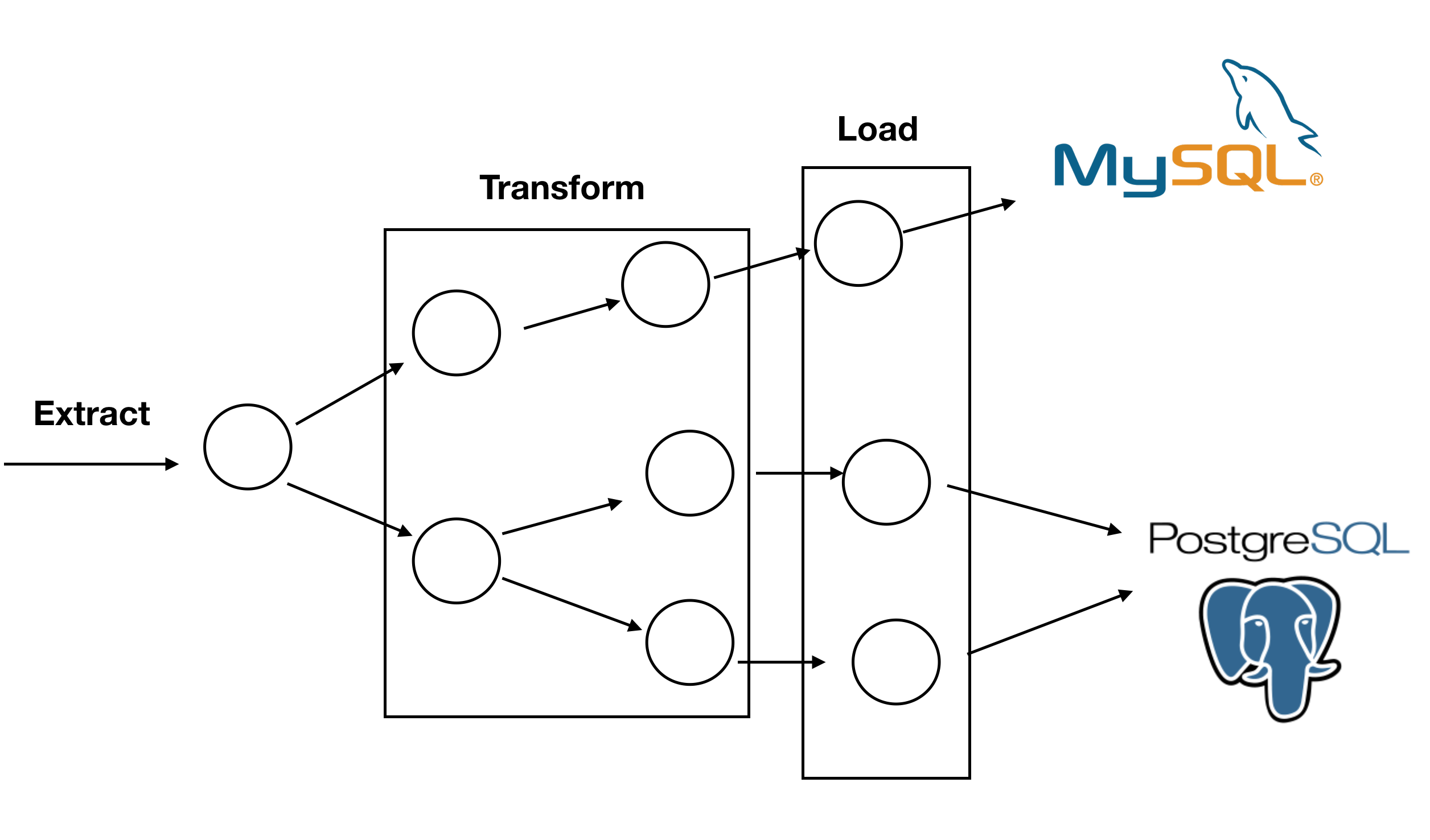
It allows you to support true fault tolerance on “Load” stage, have a parallel/distributed system and prevent side effects during data transformation.
What tasks we can solve using ETL + data pipelines approach ?
Let’s start from a simple one:
Analytics
Recently inside Doist we implemented financial dashboard which is basically a common ETL task. We extract data from different payment sources like (Stripe, PayPal …) transform this data to one representation and then save (load) everything to databases.
On the second iteration we extract data from database and transform this data into “Dash/Plotly” format then load everything to redis and display cool nd beautiful dashboard using Dash application.
Everything was made using Stairs framework. And here some benefits of this:
- We are able to deploy everything to AWS lambda (stairs allow to do that)
- It’s super easy to add new charts or change existing
- It’s super clear how data moving through our system, and which data we need for each of the chart.
Train ML model
Data pipelines are more and more popular in this field. You can see batch of solutions related to that:
Even tho this solutions not saying about ETL, in same way this tools implementing ETL concept.